Learning data engineering with the snowflake, airflow, dbt stack.
Right now I am trying to delve deeper in the area of data engineering, to do this I chose the stack comprising of Snowflake, for a cloud datawarehouse storage system, airflow to extract data from one point to another and dbt to transform the data where I want it to be.
To this goal I am now developing a project that consists of a youtube API data pipeline, I plan to extract semi-structured data from a Youtube API about popular current videos, channels and anything else the API offers, then I will dbt to structure the data and insert it into Snowflake, as Snowflake is a paid service with a limited time free trial I intend to later on move to a local instance of postgreSQL but try to learn the most of cloud datawarehousing while I can.
What is interesting about studying youtube data is that as with any other social media you can extract knowledge from any kind of field you can think of; as a techincal challenge I can also go further beyond and run a sentiment analysis algorithm to determine a genre of video, generate a summary of it, etc.
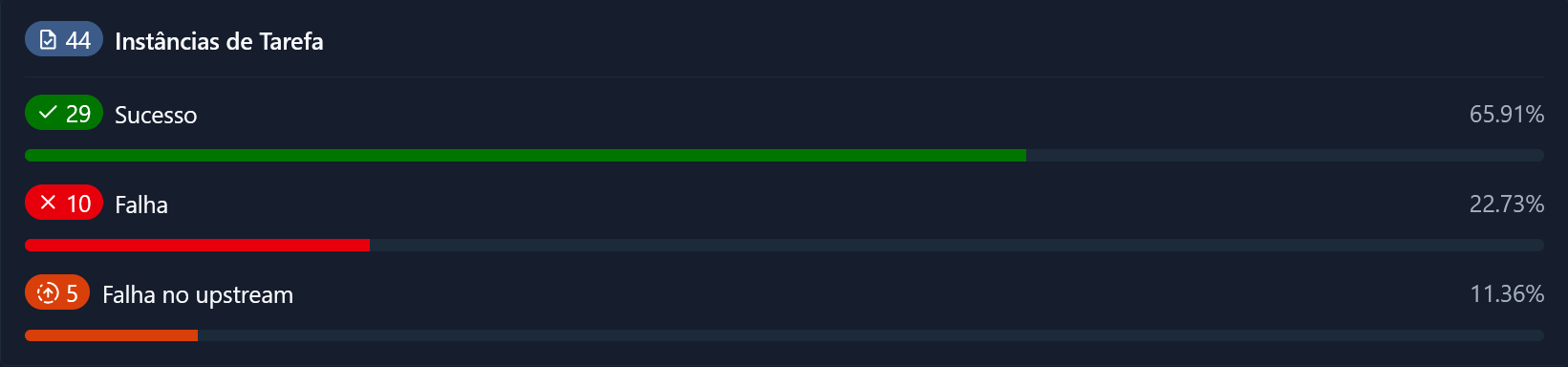
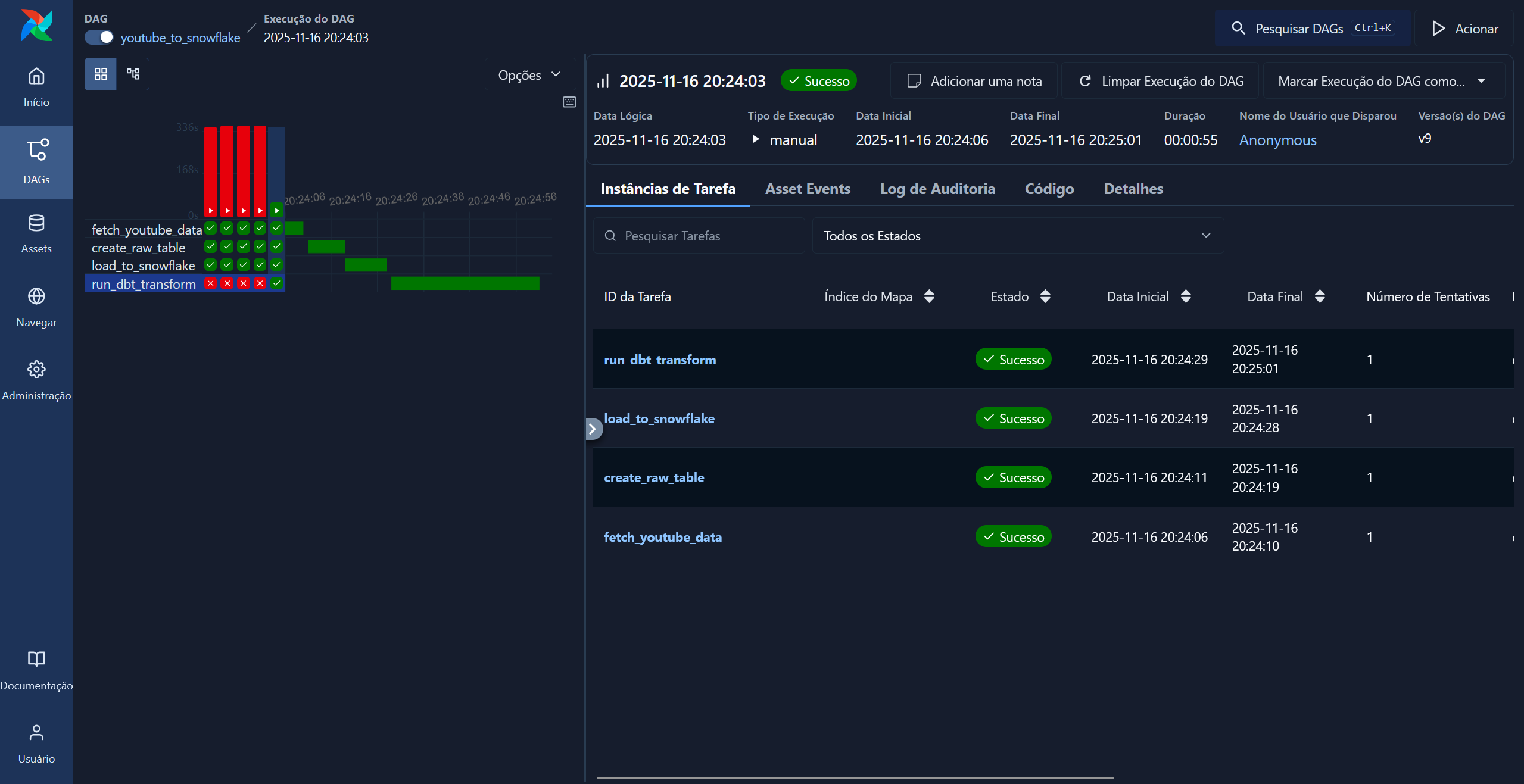 Right now I only have a very simple data pipeline that loads a video into an sql table in Snowflake; next I want to structure the data into a star schema and run more pipeline processing on it: I believe that the pace of the project will pick up now that I have a better hang of the tools I am working with.
Right now I only have a very simple data pipeline that loads a video into an sql table in Snowflake; next I want to structure the data into a star schema and run more pipeline processing on it: I believe that the pace of the project will pick up now that I have a better hang of the tools I am working with.